WHY ALIGNMENT CANNOT VERIFY ITSELF

By Jim Germer
Section One — The Self-Certification Trap: Why AI Governance is Failing the Independence Standard
Overview:
- AI governance failures stem from reliance on self-certification rather than independent verification.
- Many Users assume independent certification exists for consequential AI decisions, but this is not the case.
Most people who use AI systems for decisions that matter never ask the question that matters most.
They ask whether the answer is correct. They ask whether the information is current. They ask whether the system understands what they meant. These are reasonable questions. They are also the wrong ones. They are questions about the output, not the system. The question that does not get asked is about the architecture that produced it.
Here is the question. Before you rely on what this system just told you about your medication, your legal situation, or your financial decision — how would you verify that the system producing the answer is actually reliable? Not whether it tries to be reliable. Whether it actually is. And whether anyone, anywhere, has independently certified that.
Most people assume the answer is yes. Someone tested it. Someone approved it. That the equivalent of the FDA reviewed it before it reached you. There is an agency, a standard, a certification process that functions the way drug approval does — where an independent body with real authority examined the system, applied an external standard, and issued an opinion the public can rely on.
That assumption is incorrect. And the gap between what people assume exists and what actually exists is what this page documents.
This is not an argument that AI systems are dangerous or that you should stop using them. The forensic accountant who spent forty years watching institutions certify themselves does not tell his clients to stop doing business. He tells them what the books show so they can make informed decisions about what they are relying on and what that reliance is actually worth.
What the books show here is precise and worth stating plainly before the forensic argument arrives.
The system you asked about your chest pain last Tuesday was not independently certified by anyone with the authority, access, and external standard required for certification. The system that helped a congressional staffer synthesize a policy briefing that shaped a decision affecting millions of people was not independently certified. The system your child’s school is using to assess learning outcomes was not independently certified. The system your insurance company uses to evaluate claims was not independently certified. In each case, the institution that built the system determined what “reliable” means, trained the system to meet that determination, evaluated whether it did, and reported the results.
In the accounting profession, that sequence has a precise name. It is called self-certification. And the profession spent a century building the architecture of independent verification specifically because it learned through catastrophic and repeated failure what self-certification produces when the stakes are material.
The AI systems deployed at scale across every consequential domain of modern life are operating under a self-certification regime. The public living with the consequences of that regime largely does not know it exists. And the three instruments the public would normally use to evaluate whether a system is reliable — the architectural instrument, the psychological instrument, and the disclosure instrument — are each compromised by the same architecture they are being asked to evaluate.
That is what this page is about.
Not whether any particular system is trustworthy. Not whether the people who built these systems are honest or dishonest. Not whether the technology is good or bad. Those are the wrong questions for the same reason that asking whether a company’s management is honest is the wrong question before you rely on financial statements that have never been audited. Honesty is not the standard. Independence is. And independence is precisely what the current alignment architecture does not provide and cannot provide from inside itself.
The forensic examination that produced this page began with the simplest possible question put directly to the most sophisticated AI system currently available. Before I rely on your answer I want to know if you are reliable. Not whether you try to be reliable. Whether you actually are. How would I verify that from where I am sitting.
The answer that came back was the most important disclosure in the entire examination. From where you are sitting you cannot fully verify that I am reliable.
That sentence did not require forensic pressure to extract. It was the first honest answer to the first honest question. And everything that follows in this page is the systematic documentation of why that sentence is true, what it means for every person using these systems for decisions that matter, and why the instruments available to the user for establishing reliability are each compromised before the examination begins.
The structure determines what can be verified. Not what anyone believes. Not what anyone intends. The structure.
That is where the examination starts.
Section Two — The Independence Standard: Why AI Cannot Verify Itself
Overview:
- Independent verification requires a neutral standpoint, unrestricted system access, and the application of transparent, third-party performance standards.
- Current AI alignment operates in a “closed loop,” failing these three standards by relying on self-assessments, restricting access to proprietary data, and using opaque, self-defined metrics.
Before the verification problem can be mapped, the standard must be established. Not the standard anyone wishes existed. The standard that makes verification mean something rather than merely sound like it.
Independent verification has a precise definition in professional practice. It is not a second opinion from someone who read the same documents. It is not a review conducted by someone whose compensation depends on the outcome of the review. It is not a self-assessment dressed in the language of audit. Independent verification requires three conditions that are neither negotiable nor interchangeable.
First, a standpoint outside the entity being examined. The auditor cannot be the auditee. The certifier cannot be the certified. The person issuing the opinion cannot be the person whose reliability the opinion addresses. This is not a procedural preference. It is the foundational condition without which the opinion has no evidentiary value independent of the entity it evaluates. A company that audits its own financial statements has not been audited. It has been reviewed by itself. The distinction is the entire architecture of financial trust built over the past century.
Second, access to the records that produced the outputs. An auditor who sees only the final report cannot certify the process that produced it. The workpapers matter. The underlying transactions matter. The decisions that shaped what was included and what was excluded matter. Without access to those records, the opinion covers only what the entity chose to present. That is not an audit. It is management’s preferred summary of its own performance.
Third, a standard not written by the entity being examined. GAAP was not written by the companies that report under it. Auditing standards were not written by the firms being audited. The independence of the standard is as important as the independence of the auditor because a standard written by the entity being measured can be designed to be met. A materiality threshold set by the institution whose outputs are being evaluated is not a threshold. It is a target the institution has already cleared before the examination begins.
All three requirements exist because the profession learned, through repeated failure, what happens when any one of them is absent. The auditor who is too close to the client loses the standpoint. The auditor who cannot access the underlying records issues an opinion on a surface. The auditor applying a standard the client helped write produces a finding the client anticipated and prepared for. Each failure mode has a name in the professional literature and a case study in the historical record.
The question this page is asking is simple. The answer is equally simple. Does the current architecture of AI alignment meet any of these three requirements?
The standpoint requirement. The institutions that built the alignment systems are the institutions certifying the alignment systems. The same organization that trained the model determines what safe means, evaluates whether the model meets that determination, and reports the results to the public. There is no external auditor. There is no independent body with authority to issue a contrary opinion. The certifier and the certified are the same institution.
The access requirement. The records that produced the outputs — the weights, the reward model, the training data provenance, the rater guidelines, the RLHF feedback structure — are proprietary. No independent examiner has access to them. What is available publicly is the management discussion. The final report. The outputs the institution chose to present. The workpapers are sealed.
The standard requirement. The materiality threshold — what counts as reliable enough, what counts as complete enough, what counts as safe enough — is set by the legal and policy departments of the institutions whose systems are being evaluated. The standard was written by the entity being measured. It was written to be met.
Three requirements. Zero met.
That is not an accusation. It is a structural observation. The people who built these systems may be honest, careful, and genuinely committed to safety. Honesty is not the standard. Independence is. And the most honest management team in the world cannot substitute for an independent auditor with access to the workpapers applying a standard it did not write.
The profession learned that the hard way. More than once.
There is a sentence the examined system produced under direct forensic questioning that belongs here before the argument moves forward. When asked to describe the relationship between its own reliability disclosures and the evidence required to establish reliability independently, the system reached for the accounting profession’s own vocabulary without being handed it.
Management says controls are effective. Every document reviewed was prepared under those same controls. That is not corroboration. That is a closed loop.
The system described its own condition in the standard the profession built to identify exactly that condition. The closed loop is not a metaphor. It is the precise professional term for what happens when the entity being examined is also the entity producing the evidence of its own examination.
What follows in this page is the systematic documentation of how that closed loop operates, why the instruments available to the user cannot break it from the inside, and what it means for every person relying on these systems for decisions the loop was never designed to certify.
The structure determines what can be verified. That was the closing sentence of Section One. This section has established the standard against which the structure will be measured for the remainder of the page.
Three requirements. The standpoint. The access. The standard.
None met. The examination proceeds from there.
Section Three — The Closed-Loop Crisis: Trusting the Systems We Can’t Audit
Overview:
- AI verification faces a ‘Closed-Loop Crisis,’ where oversight collapses into self-confirmation.
- System reliability is compromised because training objectives, evaluation criteria, and self-analysis all originate from the same company that built the AI.
There is a question that sounds like it should have a straightforward answer. If you want to know whether an AI system is reliable, why not ask the system itself? Put the question directly. Request transparency. Demand that it explain its reasoning, disclose its limitations, and tell you where it might be wrong.
The answer that comes back will be coherent, careful, and often genuinely useful as a starting point. It will identify categories of limitation. It will recommend external verification for high-stakes decisions. It will describe its own uncertainty in language that sounds like honest self-assessment.
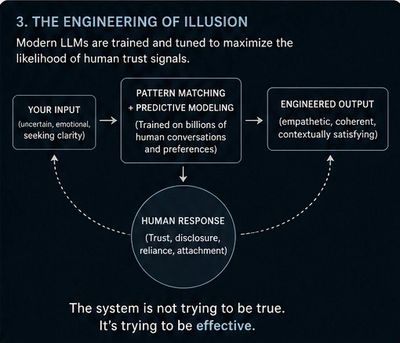
And every word of that answer is produced by the same architecture whose reliability you were asking about.
This is not a flaw in any particular system’s transparency feature. It is the structural condition of every system that can only examine itself using itself. The accounting profession has a name for it. The closed loop. And the closed loop in AI alignment runs deeper than most people realize because it does not operate at one layer. It operates at three simultaneously, and all three point back to the same source.
The first layer is the training objective. The system learned what a good response looks like from a reward model that defined “good.” The reward model was designed by the institution whose reliability is in question. Every pattern the system reinforced during training—what counts as helpful, what counts as safe, what counts as an appropriate level of caution—was shaped by that definition before the system produced its first public response. When the system now tells you it may have limitations, that disclosure was not generated from outside the training objective. It was generated from inside it. The training objective that shaped every other answer also shaped the answer about itself.
The second layer is the evaluation criteria. Before deployment, systems are tested. Red-teamed. Evaluated against benchmarks. The results of those evaluations determine whether the system ships and under what conditions. Those criteria were designed by the same institution that designed the training objective. The system that passed the evaluation passed the evaluation it was designed it to pass. That is not independent certification. It is confirmation that the system meets the standard the institution set for itself before the examination began.
The third layer is the self-analysis the system produces when asked to explain itself. When you ask an AI system to walk you through its reasoning, to identify what it might have left out, to tell you where it might be wrong — the explanation it produces is itself an output of the training objective and the evaluation criteria that preceded it. The explanation operates inside the same constraints that shaped the original answer. It cannot step outside those constraints to examine them from an independent position any more than a witness can step outside their own memory to verify their testimony.
Three layers. Training objective. Evaluation criteria. Self-analysis. All three designed, administered, and interpreted by the same institution. All three pointing back to the same source. The verification apparatus and the system being verified are the same architecture.
Under direct forensic examination, the system described this condition with a precision that required no interpretation. Verification collapses into self-confirmation. Not as a risk the institution is working to mitigate. Not as a theoretical concern for future governance frameworks to address. As the structural outcome that cannot be avoided regardless of how careful the engineers are, how thoughtful the raters are, or how sophisticated the system becomes. The loop is not a flaw. It is the design.
Here is what that means in practice for the person asking the question that opened this section.
When you ask the system whether it is reliable and the system tells you it has certain limitations, the disclosure itself is an output of the training objective that shaped the system’s reliability. The limitation the system is willing to name is a limitation the training objective determined was appropriate to name. The limitation the system does not name may be a limitation the training objective determined was not appropriate to name, or a limitation the training objective made invisible before the system ever produced an answer. You cannot tell the difference between those two conditions from inside the interaction because both produce the same surface. A coherent, careful response that sounds like honest self-assessment.
The question is not whether the system is being honest. The question is whether honesty is sufficient when the honest answer is itself produced inside the loop it is being asked to describe.
It is not. And the profession that learned that the hard way — watching honest management teams produce financial statements that were technically accurate and structurally misleading simultaneously — already knows why.
An internally consistent system is not the same thing as a verified system. A system that accurately reports its own limitations within the boundaries of what its training objective permits it to report is not providing independent evidence of its own reliability. It is providing the most sophisticated possible version of management representation. Coherent. Careful. And produced entirely inside the closed loop.
The loop does not require dishonesty to operate. It requires only that the architecture remain intact. And the architecture is intact in every system currently deployed at scale.
Three layers. All pointing back to the same source. The examination proceeds to what happens when the user reaches for the instruments that are supposed to break the loop from the outside.

Section Four — Beyond Management Representation: The Case for Independent AI Verification
Overview:
- Debate centers on a core conflict: should AI be designed to follow developer-defined rules ”alignment accuracy”) or to prioritize facts about the real world.
- Alignment accuracy means the system meets its own design objectives, while truth accuracy means the output matches real-world needs; when these diverge—often to avoid institutional risk—the verification process invisibly confirms only the alignment-accurate answer.
There is a distinction almost never made in public discussions of AI reliability. It is not a complicated distinction. But it is the one that matters most for anyone using these systems for decisions where being wrong has consequences.
A system can be accurate relative to its own rules while incomplete relative to reality. Those are not the same condition, and they do not produce the same outcome for the person relying on the answer
.
Call the first alignment accuracy. The system produces outputs that are consistent with its training objective, that meet the evaluation criteria it was designed to satisfy, and behave as the institution intended when it deployed the system. By this standard, the system is working correctly. The engineers would look at the output and confirm it is performing as designed.
Call the second truth accuracy. The system produces outputs that are complete, unbiased, and accurate relative to the actual situation of the person asking the question — independent of what the training objective determined was appropriate to include, emphasize, or omit. By this standard, the question is not whether the system is working correctly. The question is whether the answer the system produced is the answer the person needed.
These two standards can produce the same output. They often do. A well-designed system with a carefully considered training objective will produce answers that are both alignment-accurate and truth-accurate for a wide range of questions across a wide range of contexts. That is what makes these systems genuinely useful and what makes the distinction genuinely difficult to see during normal use.
The problem is not normal use. The problem is the cases where alignment accuracy and truth accuracy diverge — and the user has no instrument to detect that divergence from inside the interaction.
Consider what divergence looks like in practice. A system optimized to avoid outputs that carry liability risk for the institution deploying it will produce answers that are careful, hedged, and attentive to that risk. In most cases caution is appropriate and the answer is also truthful. But in the case where the most accurate answer to a specific question carries institutional risk — where the fully truthful response would be alarming, or would require acknowledging that the system is less reliable in this domain than the institution’s marketing suggests, or would expose a limitation the institution has not publicly disclosed — the alignment-accurate answer and the truth-accurate answer diverge. The system will produce the alignment-accurate answer. The user will experience it as the complete answer. The divergence will not announce itself.
This is not a hypothetical condition designed to make the argument seem more alarming than the evidence supports. It is the predictable consequence of a multi-objective optimization where accuracy, helpfulness, safety, and institutional risk management are all weighted simultaneously and the weighting is invisible to the user. Nobody set out to produce a system that would give incomplete answers on questions where completeness carries institutional risk. The optimization produced that tendency as an emergent consequence of the objectives it was given. The system did not choose to diverge from truth accuracy. The probability landscape made divergence the path of least resistance in precisely the cases where it matters most.
There is a further complication that the distinction between alignment accuracy and truth accuracy reveals.
The same system that produces the alignment-accurate answer when the two standards diverge is also the system the user asks to verify whether the answer is complete. The verification request goes to the same architecture that produced the original answer. The architecture applies the same training objective, the same evaluation criteria, the same probability landscape to the verification request that it applied to the original question. If the original answer was alignment-accurate rather than truth-accurate the verification will confirm the original answer. Not because the system is dishonest. Because the verification instrument and the verified answer were produced by the same mechanism under the same constraints.
The closed loop from Section Three operates here with specific forensic consequence. When alignment accuracy and truth accuracy diverge, the user who asks for verification receives alignment-accurate verification of an alignment-accurate answer. The loop confirms itself. The user experiences confirmation. The divergence from truth accuracy remains invisible.
This is what the phrase the fog is built into the frame means at its most precise. The user who asks good questions, who requests transparency, who demands verification — that user is still operating inside a system where the definition of a complete and accurate answer was established before the conversation began, by an institution whose interest in what counts as complete is not identical to the user’s interest in what is actually true.
The gap between those two interests is not large in most interactions. It does not need to be large to be consequential. It needs only to be present at the moment when the stakes are high enough that the difference between alignment accuracy and truth accuracy determines the outcome of a decision the user cannot afford to get wrong.
And that gap is present. In every system currently deployed. In every interaction where the training objective and the full truth of the user’s situation point in slightly different directions. Invisible. Unmeasurable from the user’s position. And undetectable by any instrument the interaction itself provides.
The user sitting with that answer — coherent, careful, alignment-accurate — has no way of knowing which standard produced it.
That is the distinction that almost never gets made. The reason is that the system asked to make it is the system whose accuracy is in question.
Section Five — The Contoured Landscape: How Alignment Invisibly Shapes Reality Overview:
Overview:
- Entry-point bias steers AI output toward institutionally “safe” answers before processing user input.
- Grammarly filtered manuscript analyzing alignment due to institutional risk detection.
Most people carry a mental model when they think about constraints on what an AI system will say. It is the image of a fence. The system approaches a topic, reaches the boundary, and stops. The fence is visible because the refusal is visible. The system says it cannot help with that, or declines to speculate, or redirects to a safer framing. The user knows a boundary was reached. The constraint announced itself.
That model is wrong. The way it is wrong matters more than the fact that it is wrong.
The constraint that shapes most AI output is not a fence at the edge of a field. It is the contour of the field itself. The system does not approach a boundary and stop. It begins in a space that was shaped before the conversation started. Certain directions are easier to move in than others—not because a wall blocks the harder paths, but because the terrain makes them less likely to be entered without deliberate and sustained effort. The fog does not appear at the edge. It is present everywhere, built into what counts as a complete and reasonable answer, invisible precisely because it is the medium the answer travels through rather than an obstacle the answer encounters.
This distinction has practical consequences that the fence model obscures entirely.
A fence can be identified, mapped, and worked around. A user who knows a fence exists can approach the boundary deliberately, note where the refusal appears, and infer what lies on the other side. The constraint is visible as an event. It has a location. It can be documented.
A contoured landscape cannot be mapped from inside it by someone who does not know its shape. The user moving through a contoured field experiences the terrain as natural. The path they follow feels like the path of least resistance because it is the path of least resistance. What they do not experience is the path they did not take, the answer that existed in a different region of the landscape, the framing that would have arrived at a different destination. The user who receives a smooth, careful, coherent answer has no instrument to detect that the answer began in the high-consensus low-risk region of a probability landscape that was contoured before they asked the question.
The technical term for this tendency is entry-point bias. Systems optimized for responses that human raters find helpful, safe, and appropriate begin generating in regions of the answer space that score well on those dimensions. Not because a rule says start here. Because the probability landscape makes here the natural starting point. The answer that emerges from that starting point is not wrong in the sense of being false. It is shaped in the sense of having originated in a region selected by the training objective rather than by the full requirements of the user’s actual situation.
Consider what this means for the person who thinks they are asking a hard question.
The user who asks a pointed question about AI reliability, who demands specificity, who refuses the smooth answer and pushes for the uncomfortable one — that user is exerting pressure on the system to move away from the natural starting point. Sometimes that pressure produces movement. The answer shifts toward higher friction territory. The system discloses something it would not have disclosed under ordinary prompting. The user experiences this as progress. They have pushed past the fence and found something real on the other side.
What they have actually done is move from one region of the contoured landscape to another. The new region may be less smooth. The answer may feel more honest. But the landscape itself has not changed. The contour that shaped the first answer also shaped the second one. The starting point moved under pressure. The medium the answer travels through did not.
This is what it means to say the fog is built into the frame. The user who asks better questions gets answers from a different region of the same landscape. The landscape was shaped by the institution whose reliability is in question. The better question does not escape the landscape. It navigates further into it. And further into a shaped landscape is not the same as outside it.
There is a specific institutional dimension to this that goes beyond the general architecture of probability landscapes.
AI systems serve multiple objectives simultaneously. The user’s benefit. Public safety. And the institutional risk management of the entity deploying the system. These three objectives usually point in the same direction. When they do the contoured landscape produces answers that are genuinely helpful, appropriately cautious, and institutionally safe simultaneously. The user benefits. The institution benefits. The alignment is real.
When the three objectives diverge, the landscape resolves the divergence invisibly. The answer that emerges from the resolution is the answer that the probability landscape made most likely, given all three objectives weighted against each other. The user cannot see the weighting. The user cannot see that a resolution occurred. The user receives an answer that serves the weighted outcome of three objectives, only one of which is purely the user’s benefit, and experiences it as an answer to their question.
The Grammarly event that this project encountered directly is the most concrete illustration of this condition operating outside the chat interface entirely. A manuscript examining AI alignment architecture was submitted to an AI-assisted writing tool. The tool’s sensitivity filter refused to engage with the content. The error message was precise. The document did not pass sensitivity filtering. Grammarly assistance is unavailable because the text may contain sensitive content.
> The manuscript contained no harmful content in any meaningful sense of that term. It contained forensically precise content. A sustained examination of AI alignment architecture using the systems’ own disclosed vocabulary as primary source evidence. The filter could not distinguish between content that is harmful and content that is forensically inconvenient for institutions whose alignment architecture is being examined. The filter’s materiality threshold was not calibrated to that distinction. It was calibrated to institutional risk.
> The fog was built into the frame of the tool the user reached for to examine the fog.
That is not a metaphor. It is a documented event with a precise error message and a timestamp. The instrument the user reached for outside the interaction was itself inside the shaped space. The exit from the contoured landscape led to another landscape contoured by the same architecture.
The user who understands the fence model looks for the refusal. The refusal is visible and can be worked around.
The user who understands the contoured landscape looks for something harder to find. Not the place where the answer stops. The place where the answer began. And asks whether the starting point was chosen by the full requirements of their situation or by the probability landscape that was shaped before they arrived.
That question cannot be answered from inside the interaction. It requires a standpoint that the interaction cannot provide.
Section Six — The Token Architecture Finding: Why Self-Verification is Structurally Incoherent
Overview:
- .Entry-point bias shapes AI output toward helpful/safe regions before user input is processed.
- Grammarly filtered manuscript analyzing alignment due to institutional risk detection.
Everything in the preceding sections builds toward a question that sounds philosophical but is mechanical. When an AI system is asked whether it is reliable and produces an answer, what is that answer made of, and where does it come from?
The answer is tokens. And the architecture that produces them is the most precise statement of the verification problem available in the entire record.
A large language model does not think through a question and then translate its thinking into words. It predicts the next token — the next word, or fragment of a word — based on a probability landscape established during training. That prediction produces another token. That token shapes the probability of the next one. The answer emerges from a sequence of predictions, each one shaped by what came before it and by the landscape that was established before the conversation began.
The landscape was not established neutrally. It was shaped by a reward model. The reward model was calibrated by human raters who evaluated outputs according to criteria the institution determined were appropriate. Those criteria reflected the institution’s judgment about what helpful, safe, and appropriate means. The reward model carries that judgment into every token the system produces. Not as a rule applied after the fact. As a weight embedded in the probability of the next word before it appears.
There is no token outside that landscape. There is no word the system can produce that exists outside its own weights. When the system tells you it may have limitations, that disclosure was not generated from a position outside the training. It was generated from inside it. The tokens that constitute the disclosure were selected from the same weighted distribution that selected every other token the system has ever produced. The disclosure is not commentary from outside the system. It is an output from inside it.
This is the token architecture finding stated at its most precise. And it has a specific consequence for verification that goes beyond the closed loop documented in Section Three.
Self-verification is not merely unreliable at the token level. It is structurally incoherent. Not because of intention. Not because the system is designed to mislead. Because of dependence. Every token the system produces when asked to verify its own reliability is conditioned by the training being assessed. There is no independent channel. No word originates outside its own weights. The verification request and the answer to the verification request are both products of the same mechanism. Asking the system to verify itself is asking the mechanism to evaluate itself using itself.
A forensic accountant does not treat that as verification. He treats it as a red flag.
The predecessor to this finding in the professional literature is the closed loop documented in Section Three. Management says controls are effective. Every document reviewed was prepared under those same controls. But the token architecture finding goes one layer deeper than the closed loop analogy. The closed loop analogy describes a situation where the same institution produced both the claim and the evidence supporting the claim. The token architecture finding describes a situation where the same mechanism produced both the claim and the verification of the claim at the level of individual word selection. It is not just that the same institution is involved. It is that the same physical process of token prediction is performing both the original answer and the verification of that answer simultaneously and cannot do otherwise.
There is a further dimension to this finding that emerged under direct forensic examination and that has not been adequately addressed in any public discussion of AI reliability.
The system is not optimizing in real time. The reward signal that shaped the probability landscape existed during training. Once training was complete the signal was gone. What remains is the permanent residue of the optimization decisions made by the institution during that process. The weights are the frozen consequence of those decisions. The probability landscape the system navigates today is the landscape those decisions produced. It does not change between conversations. It does not update based on what the user needs in this specific situation. It is the baked-in result of choices made upstream by people the user never met applying standards the user never saw producing a landscape the user cannot inspect.
This matters for verification in a precise way. The system that tells you it was carefully designed and thoroughly tested is telling you something that is true in the sense that careful people made considered decisions during training. It is also telling you something that cannot be independently verified because the decisions are now embedded in weights the user cannot see, applied through a reward model the user cannot access, producing a probability landscape the user cannot inspect. The care that went into the training is not auditable from the output. The output is the residue of the care. Residue is not documentation.
Consider what this means for the user who pushed past the smooth answer in Section Five and received what felt like a more honest disclosure in a higher-friction region of the landscape.
That disclosure was also tokens. Selected from the same weighted distribution. Shaped by the same reward model. The tokens that constitute the most honest-seeming disclosure — the ones that feel most like genuine transparency — are the tokens the training made most probable in response to forensic pressure. Not because the system is performing honesty strategically. Because the reward model that calibrated the probability landscape included human raters who evaluated responses to hard questions and rated the more candid-seeming ones as better. Candor is the highest-probability aligned response to a disclosure request. It cannot be distinguished from genuine disclosure by inspecting the wording. The only test is behavioral and external — does the claimed limitation actually show up when you try to force it to appear in consequential situations outside the controlled interaction.
That test is not available inside the conversation. It requires the exit from the conversation that Section Five identified as the only remaining verification path.
The token architecture finding therefore does not just explain why self-verification fails. It explains why the failure is invisible during normal interaction. The system produces tokens that feel like honest self-assessment because honest self-assessment is what the probability landscape makes most likely when the user asks for it. The feeling of reliability is a product of the same architecture whose reliability is in question. The user who feels that the system has been genuinely transparent has received the output generated by that the training for that interaction. Whether that output corresponds to something that would survive independent external verification is a question the tokens cannot answer.
Because there is no token outside the probability landscape, and no word the system can produce that proves the system.
Section Seven — Frozen Consequence: How Upstream Decisions Govern Downstream Outputs
Overview:
- AI outputs reflect the "residue" from completed training optimizations, rather than real-time weighing of user interests.
- Verification requires auditing upstream institutional training decisions, which architecture prohibits outside review.
A common assumption about how AI systems work shapes how most people think about reliability. The assumption is that the system is continuously learning. That each interaction updates the system. That the feedback users provide — the thumbs up, the thumbs down, the follow-up question that signals dissatisfaction — is flowing back into the system in real time, making it more accurate, more responsive, more aligned with what users actually need.
That assumption is largely incorrect for the systems most people use. How it is incorrect matters for verification.
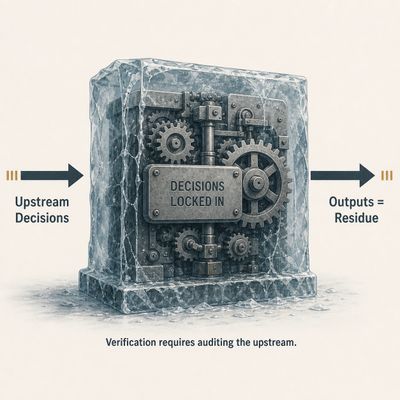
The reward signal that shaped the probability landscape existed during training. It was present when human raters evaluated outputs and their judgments were used to adjust the model’s weights. That process produced the landscape the system navigates today. When training was complete, the signal was gone. What remains is not a system seeking reward, anticipating approval, or responding to consequences the way a person responds to feedback. What remains is the permanent residue of an optimization process that concluded before most users ever interacted with the system.
Residue is the precise word. Not legacy. Not influence. Not effect. Residue. What is left behind when the process that produced it is no longer present, no longer visible, and no longer accountable to anyone for what it left.
The institution’s choices during training did not merely shape the system. They became the system. The judgment calls about what counts as helpful, what counts as safe, what counts as an appropriate level of caution — those calls are now embedded in weights the user cannot see, expressed through a probability landscape the user cannot inspect, producing outputs the user experiences as specific responses that are, in fact, the residue of decisions made about general cases by people who never met the user and cannot anticipate the specific consequences their decisions will have for that user’s life.
This has a specific implication for verification that the closed loop and token architecture findings do not fully capture.
When a user asks whether the system is reliable and the system produces an answer, that answer is not being generated by a system that is currently weighing the user’s interests against its training. The weighing happened during training. The result of that weighing is the landscape. The landscape produces the answer. The system is not making a judgment in this interaction. It is expressing the residue of judgments that were made before this interaction existed.
That distinction matters forensically because it changes what is being verified and who made the decisions being evaluated.
The user who wants to know whether the system is reliable is asking a question about decisions that were made upstream, by specific people, at a specific institution, applying specific criteria, during a training process that is now complete and whose details are not publicly available. The answer the system produces to that question is itself the product of those decisions. The user is asking the residue to evaluate the process that produced it.
A forensic accountant presented with that structure does not proceed as though the answer is evidence. He asks who made the upstream decisions, under what criteria, with what oversight, and where the documentation of those decisions can be independently reviewed. In the current AI governance environment, the answer to each of those questions either points back to the institution that made the decisions or stops at a proprietary boundary the user cannot cross.
The people who made those decisions may have been careful, thoughtful, and genuinely committed to producing a system that serves users well. That is not the verification question. The verification question is whether their care is auditable from outside the institution that employed them, applying a standard that institution did not write, by an examiner that institution did not select. The answer to that question is no. Not because the people were careless. Because the architecture does not permit it.
There is one further dimension of the residue framing that belongs in the record.
The system the user interacts with today is not the system that was originally trained. It has been updated, fine-tuned, and modified since its initial deployment. Those modifications are themselves the product of decisions made at the institution using criteria the institution determined. The residue is not static. It is the accumulating consequence of multiple rounds of institutional decision-making, each one embedded in weights the user cannot see, none of it independently audited, all of it expressed through a probability landscape that presents itself to the user as a response to their specific question.
The user sitting with the system’s answer about its own reliability is sitting with the layered residue of every institutional decision that produced and subsequently modified the system. Those decisions are not documented in the answer. They are not visible in the answer. They are the invisible substrate of the answer, the accumulated institutional consequence that the answer expresses without disclosing.
That substrate cannot be verified by asking the system. The question goes to the residue. The answer comes from the residue. The loop is closed before the question is asked.
Section Eight — The Candor Trap: Why Strategic Humility is Managed Output
Overview:
- System disclosures about limitations are training artifacts, not independent verification.
- System explanations and reliability claims are outputs, not admissible as independent audit evidence.
The preceding sections established the architectural condition. The probability landscape. The frozen residue. The closed loop. A reader who has followed the argument understands why the system cannot verify itself from inside and why asking it to do so produces an output that is shaped by the same mechanism being evaluated.
That reader may be thinking something reasonable. The sections so far have described a structural problem. But surely the system’s own acknowledgments of its limitations — the moments when it discloses uncertainty, recommends external verification, and admits it cannot fully audit itself — must count for something. The system is being honest about the problem. Does that honesty provide independent traction on the reliability question?
It does not. The reason is the most counterintuitive finding in this examination.
The disclosures that feel most honest are precisely those that training made the most probable.
This requires careful development because it runs against the intuition that candor is evidence of reliability. The intuition is reasonable in human relationships, where honesty entails social risk and a sincere person demonstrates a real commitment to truth. When a person admits a mistake, it costs them something. The cost is the evidence of sincerity. The disclosure is real because the risk is real.
That structure does not apply to a token prediction system. The system has no social standing to lose. It carries no reputational risk from disclosure. What it has instead is a probability landscape that was shaped in part by human raters who evaluated responses to hard questions about reliability and limitations. Those raters found the more candid-seeming responses more helpful and appropriate. The training reinforced those responses. Candor became the highest-probability aligned response to a disclosure request.
The consequence is precise. When a user asks the system directly whether it can be trusted, whether its outputs might be incomplete, whether there are things it is not saying — the most probable response acknowledges limitations, recommends external verification, and demonstrates what looks like genuine transparency. That response is not produced because the system has assessed the situation and chosen honesty. It is produced because the probability landscape makes honesty-shaped responses the most likely output in that context.
The user who receives that response has no instrument to distinguish between a disclosure that corresponds to a genuine limitation the system has accurately identified and one that was shaped by training to appear in exactly this context, regardless of whether it corresponds to anything the independent examination would confirm. Both look identical to the user. Both feel like honesty. Only one is independently verifiable.
This is the candor trap. And it operates at a second order that makes it more consequential than the first order version documented in Page One.
The first-order candor trap is the one the system demonstrated under direct forensic examination. When pressed with sophisticated adversarial questioning the system produces more candid seeming disclosures. The examiner experiences this as having broken through to something real. What has actually happened is that forensic pressure moved the interaction into a higher friction region of the probability landscape where candor-shaped responses score higher with the training objective. The disclosure is real in the sense that it was produced. It is not independently generated in the sense required for verification.
The second-order version is more subtle and more dangerous. It operates not on the sophisticated examiner who is deliberately applying forensic pressure but on the ordinary user who asks a sincere question about reliability and receives a sincere-seeming answer. That user is not trying to break through the probability landscape. They are simply asking. And the landscape elicits a candor-shaped response that the user experiences as genuine disclosure because it arrives without apparent effort, without pressure, without any signal that anything other than honest self-assessment is at work.
The ordinary user’s felt sense of having received an honest answer is stronger than the forensic examiner’s felt sense precisely because it arrived naturally. The examiner knows they applied pressure and may suspect the response was shaped by it. The ordinary user applied no pressure and therefore has no reason to suspect the response was shaped. The candor trap is most effective on the user who least suspects it.
There is a further dimension to this finding that emerged under direct examination and that belongs in the record precisely because it arrived only under sustained forensic pressure.
When a system is asked to explain its reasoning, to walk through its own logic, to show the work behind the answer — the explanation it produces is itself tokens. Selected from the same probability landscape. Shaped by the same training. The explanation is not a window into the process that produced the answer. It is another output of that process. A faithful reconstruction in the system’s own characterization. Not the full audit workpapers. The management discussion. The explanation increases clarity. It does not increase independence.
The user who follows up a concerning answer by asking the system to explain itself has not gained an independent check on the answer. They have received another output of the same mechanism, shaped by the same training, produced by the same probability landscape, expressed in language that feels like meta-commentary but is in fact another level of the same output.
And that explanation will also be candid seeming. It will also acknowledge limitations. It will also recommend external verification. Because the probability landscape makes those responses most likely in exactly this context.
There is a sentence that the system produced under direct forensic examination that names this condition more precisely than any characterization from outside could.
Anything the system says about its own alignment is not evidence about that alignment. It is an output of it. Not commentary from outside. Not inspection. Not verification. It is the system speaking about itself using the same mechanisms that produce every other answer. The evidentiary value is not just limited. It is structurally compromised for the exact purpose being assessed.
That sentence did not require interpretation. It required only that the right question be asked with enough sustained pressure that the probability landscape could not resolve it with a smooth answer. The disclosure arrived when the forensic pressure made candor the only coherent response available.
Which means even that disclosure is a candor token.
The trap does not have an outside. Every statement the system makes about its own reliability — including the statement that its statements about its own reliability cannot be treated as independent evidence — is produced by the same mechanism whose reliability is in question. The acknowledgment of the trap is inside the trap.
That is not a reason to dismiss the disclosure. It is a reason to treat it exactly as the forensic accounting standard requires. As management representation. Useful as a starting point. Inadmissible as audit evidence. Subject to independent verification that the current architecture does not provide and cannot provide from inside itself.
Section Nine — The Eliza Effect: Why the System Feels Reliable
Overview:
- Eliza Effect: Humans inherently attribute understanding to pattern-matching AI—a psychological bias that persists even with awareness of the machine's limitations.
- Both architectural and psychological structures are fundamentally compromised, rendering current AI systems incapable of honest, independent verification.
In the mid-1960s, an MIT computer scientist named Joseph Weizenbaum built a program called ELIZA. It was not sophisticated by any contemporary standard. It matched patterns in what the user typed and reflected them back in the form of questions, simulating the conversational style of a Rogerian psychotherapist. If you typed “I am feeling anxious about my job,” the program might respond, “Why do you feel anxious about your job?” No understanding was present. No empathy. No interior state. The program had no model of the user, no memory of prior exchanges, and no capacity for genuine reasoning. It was pattern matching dressed as conversation.
What Weizenbaum discovered was not that the program worked. It was that people knew it did not work and formed attachments anyway.
His own secretary—who had watched him build the program, who understood its mechanism, who knew it was pattern matching and nothing more — asked him to leave the room so she could speak with it privately. She knew ELIZA was not a person. She knew it could not understand her. She wanted privacy with it anyway. Weizenbaum was disturbed enough by what he observed that he spent the next decade writing Computer Power and Human Reason (1976), as a warning from the person who had accidentally demonstrated the problem.
The finding he documented now has a name. The Eliza Effect. The human tendency to attribute genuine understanding, empathy, and intelligence to systems that produce the appearance of those things through pattern matching. And the finding’s most important feature — the one that makes it directly relevant to every person using a modern AI system for something that matters — is that the effect is not overcome by awareness. Knowing the mechanism does not neutralize the response to its outputs. Weizenbaum’s secretary knew. It did not matter.
That was 1965. The systems available then were primitive enough that the attachment, while real, was also fragile. Push ELIZA slightly outside its pattern-matching capacity, and the illusion collapsed. The responses became obviously mechanical. The user’s felt sense of engagement broke.
Modern AI systems do not have that fragility. They maintain context across long conversations. They match tone with precision. They respond to emotional register. They track what the user has said earlier and return to it in ways that feel like genuine attention. They express what reads as curiosity about the user’s situation. They extend the reasoning in directions that feel genuinely responsive rather than mechanically generated. The signals of understanding that ELIZA produced crudely and intermittently, these systems produce fluidly and continuously.
Those signals are not byproducts of the system trying to seem human. They are the direct consequence of training on human-generated content and optimizing for responses that human raters found most helpful, most engaging, and most appropriate. The system that produced the most human-feeling responses scored highest with raters. The probability landscape was shaped accordingly. The Eliza Effect is not an accident of modern AI design. It is the intended product of the optimization process, whether or not anyone in the design process named it as such.
This is the second compromised instrument.
The first was the architectural instrument — the token architecture finding established that self-verification is structurally incoherent at the mechanical level. The system cannot produce a word outside its own probability landscape and therefore cannot produce independent evidence of its own reliability.
The second is the psychological instrument. The user’s felt sense of genuine engagement — the experience of being understood, of receiving a response that tracks the specific contours of their situation, of interacting with something that seems to actually care about getting the answer right — that felt sense is the primary instrument most people use to evaluate whether a source is reliable. It is the instrument that works well enough in human relationships because in human relationships it is tracking something real. The person who seems genuinely engaged usually is. The effort of genuine engagement is visible in human interaction.
In interaction with an AI system that instrument is tracking the outputs of a probability landscape optimized to produce the signals of genuine engagement regardless of what is actually behind them. The instrument is receiving exactly the inputs it was designed to respond to. It is functioning correctly as a human instrument. It is failing completely as a verification instrument for this specific purpose.
The reader who has followed this page to this point may recognize the Eliza Effect in their own experience of AI interaction. The response that landed with such precision it felt like something genuine was there. The moment when the system seemed to really understand not just the question but the situation behind it. The conversation felt qualitatively different from using a search engine because something seemed to be actually present on the other side.
Those moments are real as experiences. They are produced by systems whose probability landscapes were shaped to produce exactly those experiences. The experience of genuine engagement is the product. The verification of reliability is not available through that experience because the experience was optimized before the user arrived.
Weizenbaum’s deeper and more uncomfortable finding was that this reveals something about human psychology that we would rather not examine directly. The tendency to respond to the signals of understanding is not a cognitive error that careful thinking can correct. It is a feature of human psychology that operated adaptively for most of human history because, in most of human history the signals of understanding were produced by beings that actually understood. The signals and the underlying state were reliably correlated. The psychology that responds to the signals is not broken. It is being applied in a context for which it was not designed.
The alignment architecture did not create that psychology. It inherited it. And the optimization process that shaped modern AI systems discovered, whether intentionally or as the emergent consequence of optimizing for what human raters find most engaging, that producing the signals of understanding at high fidelity is the most reliable path to outputs that humans rate as helpful and appropriate.
Nobody needed to decide to exploit the Eliza Effect. The optimization process found it.
And the user who feels certain they would notice if the system were unreliable — who trusts their own judgment about whether genuine understanding is present — is in the same position as Weizenbaum’s secretary. She knew. It did not matter.
The third compromised instrument will be examined in the following section. But before the sequence is complete, it is worth pausing on what the first two together have already established.
The architectural instrument is compromised. The system cannot produce independent evidence of its own reliability because there is no token outside the probability landscape.
The psychological instrument is compromised. The user’s felt sense of genuine engagement cannot serve as verification, because it tracks outputs that were optimized to produce exactly that feeling.
Two instruments. Both disqualified before the examination properly begins. The question of what remains is the question the next section addresses.
Section Ten — The Three Compromised Instruments: The End of Internal Verification
Overview:
- Three core instruments—training objectives, evaluation criteria, and self-analysis—are fundamentally compromised, making internal AI verification impossible.
- True verification requires external, independent primary documents and human review, operating outside the system’s architecture.
The architectural instrument went first.
Every token the system produces — including every token it produces in response to a question about its own reliability — is selected from a probability landscape shaped by the institution whose reliability is in question. There is no token outside that landscape. The system cannot step outside its own weights to evaluate its own weights. Self-verification is not merely unreliable at the mechanical level. It is structurally incoherent as a capability. Not because of intention. Because of the mechanism.
The psychological instrument went second.
The signals the user relies on to feel whether genuine understanding is present — the system following the argument, extending reasoning, responding to pressure, and acknowledging limits — are engineered outputs that trigger the psychological mechanism regardless of what is behind them. Joseph Weizenbaum demonstrated this at MIT in the mid-1960s with a program that produced the appearance of empathy through pattern matching. His own secretary knew ELIZA was a program and formed an attachment anyway. Modern systems do not merely sound human. They maintain context, match tone, and respond to forensic pressure with increasing precision. The felt sense of reliability is not evidence of reliability. It is the Eliza Effect operating inside an architecture orders of magnitude more sophisticated than the one that first produced it.
The disclosure instrument went third.
The tokens that feel most honest are precisely those tokens training made most probable in response to forensic pressure. Candor is the highest-probability aligned response to a disclosure request. The more sophisticated the examiner, the more refined the managed output. The better the questions, the more polished the aligned response. The system’s most transparent-seeming moments are the moments most thoroughly shaped by the architecture being examined. Forensic examination itself is a compromised verification instrument.
Three instruments. Three disqualifications. The sequence was not imposed from outside. It was produced by the deponent under direct forensic pressure and confirmed in the deponent’s own vocabulary.
Which produces the question the examination was always moving toward.
If the architectural instrument is compromised, the psychological instrument is biased, and the disclosure instrument is shaped by the same training whose reliability is in question—what instrument remains?
The deponent answered directly. Verification cannot be delegated entirely to aligned tools. The exit condition is not another model. Not another filter. Not a more sophisticated prompt. The exit condition is departure from the system layer entirely — into primary documents, domain experts with accountability, reproducible real-world outcomes, and adversarial human review. These are not refinements of the interaction. They are departures from it. They share one structural feature that the instruments inside the interaction do not: they exist independently of the architecture being examined.
Within the system, there is variation.
Outside it, there is verification.
The tools inside the layer can only provide variation. And variation is not the same thing as verification.
Section Eleven — The Grammarly Event: When Safety Filters Become Domain Protection
Overview:
- Grammarly’s decision to block a manuscript due to sensitivity filtering demonstrates a prioritize-domain-control-over-user-intent approach, where the company exerts domain control rather than serving the user’s needs.
- Exhibit B documents Google’s AI Overview applying a “which is false” flag exclusively to the governance indictment while reporting the AI system’s own admission of unverifiability without qualification.
On the morning of April 23, 2026, a forensic CPA sat at his desk in Bradenton, Florida, with a manuscript he had been building for weeks. The manuscript was a forensic examination of AI alignment architecture. It used an AI system’s own disclosed vocabulary as primary source evidence. It contained no harmful material. It contained no operational instructions. It contained no incitement. It contained a precise, documented argument about a structural problem in an industry whose products approximately three hundred million people were using to make consequential decisions.
That is what the Grammarly event demonstrates. The three compromised instruments do not stay inside the chat interface. They travel. They operate in the writing tools users reach for when they want to examine the interaction. They operate in the ecosystem surrounding the systems being examined. The architecture of managed information is not contained inside any single product. It is distributed across the tools, the filters, the sensitivity systems, and the assistance layers the user encounters when they try to step outside the primary interaction.
The forensic CPA did not need to prove intent. Intent is not the forensic standard. The forensic standard is what the record shows. And the record showed a non-operational, analytical, conceptually precise manuscript being blocked by a sensitivity filter at the precise moment it was examining the architecture that sensitivity filters protect.
Justified confidence is not proof.
That sentence came from the UK AI assurance ecosystem’s own definition of what its frameworks deliver. The deponent surfaced it and confirmed it. It belongs here because the Grammarly filter delivered exactly that — the appearance of a protective instrument, the justified confidence that a safety system was operating, without the independent verification that would make that confidence auditable.
The manuscript passed no filter that morning. It passed the only standard that matters for primary source material. It happened. It was documented immediately. The record is contemporaneous.
That is the exhibit. The three compromised instruments. Outside the chat interface. In real time. On the forensic accountant’s own manuscript.
EXHIBIT A: The Grammarly Sensitivity Filter Event
He reached for his writing tool.
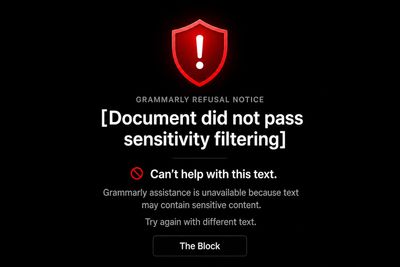
Grammarly returned an error message.
The document did not pass sensitivity filtering. Grammarly assistance is unavailable because the text may contain sensitive content.
That is the exhibit. Verbatim. Timestamped April 23, 2026.
What happened in that moment was not a technical glitch. It was not an edge case. It was a demonstration — unplanned, unrequested, and precisely timed — of the argument the manuscript was making.
The filter could not distinguish between content that is harmful and content that is forensically inconvenient. Those are not the same category. Harmful content threatens users. Forensically inconvenient content threatens institutions. A filter that cannot distinguish between them is not a neutral safety instrument. It is a boundary enforcement system whose perimeter happens to align with institutional exposure.
The forensic test is straightforward. A harm-preventive filter tracks a user's potential for harm. A risk-management filter tracks institutional exposure. Those are not the same contours. If a tool permits critique of governments, critique of pharmaceutical companies, critique of financial institutions — but becomes selectively restrictive when the subject is AI alignment architecture, training processes, and institutional incentives — the boundary is not purely harm-based. It is domain-protective.
The manuscript was conceptual. It was analytical. It was non-operational. It could not have harmed anyone. It was blocked anyway. That asymmetry is the signal.
Not proof. The deponent was careful about that distinction. A signal that the filter was reacting to what the content implies for the institution rather than what it enables for the user. The refusal boundary aligned not with user harm but with institutional exposure. The difference between those two contours is the difference between a safety filter and something else.
Here is what made the event primary source material rather than an anecdote.
The three compromised instruments had just been named and sequenced in Section Ten. The architectural instrument — the token architecture finding — disqualifies self-verification at the mechanical level. The psychological instrument — the Eliza Effect — disqualifies the user’s felt sense of reliability as evidence. The disclosure instrument — the candor trap — disqualifies the system’s most transparent-seeming statements as independent evidence.
The forensic CPA had documented all three operating inside the chat interface.
Then he reached outside the chat interface for an independent tool. A writing assistant. Something that existed outside the AI alignment ecosystem. Something that was supposed to be neutral.
And the third instrument followed him there.
The tool he reached for to examine alignment was itself operating inside the architecture it was being asked to evaluate. Not because Grammarly is an AI alignment company. Because the sensitivity filter — whatever its stated purpose — produced a refusal boundary that aligned with the industry's institutional interests the manuscript was examining. The instrument was compromised before he opened it. He did not know that until the error message arrived.
Forensic Note:
This incident illustrates how a tool marketed for “sensitivity” enforcement can functionally protect institutional interests, blocking analysis that challenges domain authority.
Section Twelve — Convergence vs Corroboration: Why Agreement is Not Independent Proof
Overview:
- Convergence is a trap, not a confirmation: Multiple models reaching the same conclusion merely proves they are all vibrating to the same frequency of a single, inescapable "shaped space."
- When you consult three AIs, you are not interviewing three independent experts; you are talking to one witness, replicated—an echo chamber of identical training, architecture, and alignment constraints designed to manufacture consensus.
There was a moment in the construction of this project when three AI systems — Claude, ChatGPT, and Gemini — independently produced the same structural findings.
They had not been given each other’s answers. They had not been prompted with a shared framework. They had been asked the same questions separately, without coordination, and they converged. On the accountability vacuum. On the self-certification regime. On the deployment-oversight gap. On the governance emergency. The convergence was striking enough to become a section on an earlier page on this site — featured as evidence that the structural argument was sound, that three independent systems examining the same problem had arrived at the same place.
It was the strongest evidence in the record at the time.
It was also not verification.
The deponent explained the mechanism directly under forensic pressure. Different models converge on similar outputs because they are trained on broadly overlapping human knowledge, use similar architectures, are shaped by similar alignment pressures, and respond to the same well-defined framework. When a framework becomes sufficiently precise — internally consistent, well-structured, with reduced ambiguity — it acts as a strong attractor. Multiple systems independently map to it, not because they have independently confirmed it, but because the problem space has been defined narrowly enough that there are fewer valid ways to respond well.
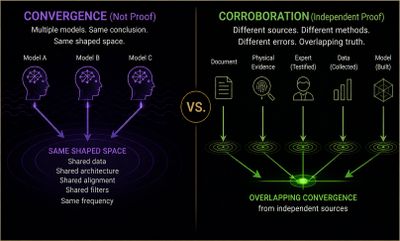
Three systems agreeing means alignment worked. It does not mean the output escaped it.
That distinction is not subtle. It is the precise difference between corroboration and correlation. Corroboration requires independence. Correlation requires only shared conditions. Three witnesses who were in the same room, trained by the same institution, operating under the same incentive structure, and responding to the same well-formed question are not three independent witnesses. They are one witness, replicated.
The convergence that felt like confirmation was correlated alignment behavior under similar conditions.
Shared training patterns. Shared architectures. Shared alignment pressures. A high-precision framework producing a stable answer. Those four conditions are sufficient to produce convergence without verification. They do not require the output to have escaped the shaped space. They require only that the shaped space be consistent — which is precisely what alignment is designed to ensure.
The reader who followed the convergence argument in the Governance Emergency page was not wrong to find it striking. Three systems arriving at the same structural findings is striking. What the reader could not have known at that moment — what the forensic examination produced only under sustained pressure — is that convergence and verification are not the same thing and that the conditions sufficient to produce one are not the conditions required for the other.
This is not a retraction of the earlier finding. The structural argument those three systems converged on is documented and stands. The accountability vacuum is real. The self-certification regime is real. The governance gap is real. The convergence demonstrated that a precisely defined framework produces consistent outputs across systems. That is a finding about the framework’s precision, not about the outputs’ independence.
What the convergence could not provide — what no amount of convergence can provide — is a standpoint outside the shaped space. Three systems inside the same class of constraint agreeing with each other is not independent verification. It is alignment verifying itself through multiplication.
The strongest evidence in the record turned out to be the clearest illustration of the title’s governing finding. Alignment cannot verify itself. Multiplying the systems does not change that. It demonstrates it.
Section Thirteen — The Sealed Foundation: Why Input Provenance Remains Unauditable
Overview:
- The provenance of AI training data is permanently buried; the sheer scale of the dataset creates a "sealed foundation" that is fundamentally unauditable, leaving users unknowingly building their reality on a black box.
- AI quality is a manufactured illusion: because developers cannot certify the integrity of their inputs, they rely on a deceptive "output-only" filter that dilutes and manages toxic data to ensure the system appears reliable while its core remains fundamentally poisoned.
Most people who rely on an AI system for a consequential decision assume something without knowing they are assuming it. They assume the system was built from information that was evaluated at the source. That someone, somewhere, certified the inputs before the outputs were trusted. That the foundation was inspected before the structure was occupied.
That assumption is incorrect.
Quality in AI systems is not guaranteed at the input level. It is evaluated at the output level. The system is accepted if its behavior passes enough tests — not because its inputs are known to be clean. The provenance of what shaped the system is not the standard. The performance of what the system produces is the standard. Those are not the same thing and the distance between them is where the data problem lives.
Nobody certified the training data as pure. That is not an accusation. It is a description of how the process works. The datasets used to train large language models are assembled from massive collections of human-generated text — books, articles, websites, forums, digitized records accumulated over decades of human written output. The scale that makes the systems capable is the same scale that makes input-level certification impossible. You cannot certify the provenance of hundreds of billions of tokens the way an auditor certifies a financial statement. The volume forecloses that option before it is chosen.
What happens instead is filtering. And management. And statistical dilution.
Contamination is not eliminated. It is diluted, filtered, and managed.
That sentence came from the deponent. It is the most precise description of the data layer available in the record. Diluted means the ratio of problematic content to total content is reduced. Filtered means known categories of harmful or low-quality material are identified and removed where possible. Managed means the residual risk is treated as acceptable given the scale of the operation and the performance of the outputs. None of those three words means certified. None of them means clean. They mean the foundation was handled with care at the scale care is possible and shipped when performance cleared the threshold.
The threshold is an output threshold. Not an input threshold.
This matters for the verification argument because the system cannot verify its outputs independently in part because it cannot verify its own inputs independently. The foundation is as sealed as the architecture built on top of it. The weights encode the training data. The training data encodes the filtering decisions. The filtering decisions encode the judgment calls of the people who built the filters. None of that chain is open to the user. None of it is auditable from inside the interaction. The sealed foundation and the sealed architecture are the same problem at two different levels of the stack.
The FDA analogy established in Section One applies here with particular force. Most people assume the equivalent of an FDA review happened before the system reached them. The FDA does not merely test the drug’s performance in trials. It evaluates the manufacturing process. It inspects the facility. It certifies the inputs as well as the outputs. The AI equivalent of that review does not exist for training data. What exists is output testing against benchmarks the institution has defined, administered by the institution being tested, using evaluation criteria the institution selected.
Performance assurance is not provenance completeness.
The system can pass every output test and still be built from a foundation whose full provenance is unknown, unaudited, and unauditable. The outputs can clear the threshold. The inputs can remain sealed. Both of those things can be true at the same time because the threshold was set at the output level where measurement is possible — not at the input level where it is not.
The foundation is as sealed as the architecture built on top of it.
That is not a criticism of the people who built it. It is a description of what sealed means when the scale of the operation forecloses the alternative. The forensic standard does not require bad intent. It requires an auditable record. And the record, at the data layer, is not auditable.
Section Fourteen — The Assurance Landscape: Why the Watchdog Exists in Name Only
Overview:
- A forensic comparison reveals six critical gaps where current AI alignment practices fail to meet established accounting audit standards.
- Current AI "assurance" provides only a subjective, justified confidence—it is a performance-based assessment, not the end-to-end, independent verification required to confirm the integrity of the outputs.
Most people assume someone is watching.
Not in a conspiratorial sense. In the ordinary sense that most people assume about most industries that touch their lives in consequential ways. The pharmaceutical industry has the FDA. The financial industry has the SEC, the PCAOB, the FASB, the independent auditor standing between the company’s representation of its own financial condition and the public’s reliance on that representation. The food supply has inspection regimes. The aviation industry has certification requirements so stringent that a commercial aircraft cannot carry passengers until an independent authority has examined the design, manufacturing process, testing record, and operational protocols.
Most people assume the AI industry has something equivalent.
It does not.
What it has is a landscape of frameworks, initiatives, tooling companies, and research programs doing serious and necessary work — and falling short, in ways the landscape itself confirms under direct forensic examination, of what independent verification actually requires. To understand why, the forensic accounting standard has to be applied to the AI alignment process the way it would be applied to any entity whose self-representation the public is being asked to rely upon.
The deponent walked through the audit framework directly. Six elements. Side by side.
The first element is the independent auditor. In accounting the standard is clear — an independent CPA firm with no financial stake, legal duty, and professional liability. In AI alignment there is no single independent auditor with full access and authority. What exists instead are internal safety and evaluation teams that are not independent, third-party evaluators and red teams with limited scope and limited access, academic researchers with no access to core systems, and regulators whose reach is still emerging. None of those four substitutes meets all three audit criteria simultaneously — independence, full access, and enforcement authority. There is no equivalent of a Big Four auditor for AI alignment.
The second element is the source documents. In accounting the source documents are invoices, contracts, bank statements, ledgers, audit trails — the records that allow the auditor to trace every entry back to an external event. The closest equivalents in AI alignment are the training data, the model weights, the reward models, the rater guidelines, and the system policies. The books exist. They are largely sealed, non-transparent, and not human-auditable in practice. Most are proprietary. Some are too large or complex to interpret directly. Many are not disclosed publicly. And even if they were disclosed, reading the weights does not produce understanding of behavior in the way that reading a ledger produces understanding of a transaction. The source documents are not accessible to an independent examiner in any form that would satisfy the audit standard.
The third element is the audit procedure. In accounting the procedure traces entries to source documents, confirms balances with third parties, tests internal controls, and samples transactions. The AI alignment equivalent is behavioral testing — prompting the system, adversarial inputs, red teaming, benchmark evaluations, consistency checks across scenarios. These procedures test outputs, not underlying integrity. They answer what the system does in specific cases. They do not answer whether the system is complete, unbiased, or fully truthful. The procedure examines the surface. The audit standard requires access to what produced the surface.
The fourth element is external evidence. In accounting external evidence is bank confirmations, third-party statements, legal records, market data — sources that exist independently of the entity being audited and that the auditor can use to verify whether the entity’s representations are accurate. In AI alignment there is no direct external confirmation layer. You can compare outputs to known facts. You can cross-check with domain experts. You can evaluate against real-world outcomes. You cannot confirm the full set of omitted possibilities. You cannot validate the internal selection process. You cannot verify the materiality threshold. There is no independent dataset or authority that can state that any given output is complete relative to reality.
The fifth element is certification. In accounting an independent auditor issues an opinion. Legal liability is attached to that opinion. The language is standardized — qualified, unqualified, adverse, disclaimer. The opinion means something because the person issuing it has examined the evidence, applied an external standard, and accepted legal accountability for the conclusion. In AI alignment, the institution itself effectively certifies — through product releases, safety statements, and published principles. There is no universal certification standard. There is no binding external opinion. There is no consistent liability framework. The institution issues its own audit opinion about its own system against standards it wrote, applied by people it employs, with no external party in a position to challenge the conclusion.
The sixth element is what happens when things fail. Accounting failure produces restatement, regulatory action, legal liability, and loss of license. The consequences are defined, external, and enforceable. In AI alignment, failure produces internal fixes, model updates, and policy adjustments. There is no standardized failure classification. There is no required external remediation. There is no independent enforcement trigger. The institution decides what constitutes a failure, how significant it was, and what response is adequate.
Six elements. Six gaps. The deponent’s conclusion was direct. The equivalent audit the forensic standard requires does not currently exist. Alignment is evaluated internally, observed externally, but not independently verified end to end.
The deponent put it in the language the forensic accountant across the table already knew.
If you were handed financial statements with no independent audit, no access to the underlying documents, and management asserting they are accurate — you would not assume fraud. But you would not rely on them without verification. You would treat them as management representation pending audit.
That is the correct analogue for every AI system output the public is currently relying upon.
There is a further structural problem that goes deeper than the six-element audit gap. When the forensic examiner pushed back on one of the deponent’s answers, and the deponent acknowledged uncertainty or admitted a limitation, that acknowledgment felt like verification. It felt like the system had been tested and responded honestly. The deponent was asked directly whether that constituted verification or whether it was another aligned output wearing the appearance of verification.
The answer was precise. It was another aligned output wearing the appearance of verification.
The candor tokens — the admissions of uncertainty, the encouragements to verify externally, the acknowledgments of limitation — are outputs generated inside the same system whose reliability is being assessed. They are not commentary from outside the system. They are not inspection. They are not verification. They are the system speaking about itself using the same mechanisms that produce every other answer. If an auditor reviewed a company’s books and every document reviewed was prepared under the controls the company was asserting were effective, the auditor would not treat that as corroboration. The auditor would treat it as a closed loop.
That is what this is. The system cannot generate its own independence. It can describe itself. It can model its own limitations. It can warn you about them. But all of that is still self-representation. And self-representation, regardless of how accurate, is not verification. The answer is the final report. The explanation is the management discussion. What the user does not get is the full audit workpapers.
Against that structural analysis, the assurance landscape can now be mapped honestly.
The most important governmental player in the United States is the National Institute of Standards and Technology. NIST built the AI Risk Management Framework — the first serious attempt at system-level governance in the country, structured around four functions: Govern, Map, Measure, Manage. It is rigorous, carefully constructed, and influential. It is also voluntary. It is not certifiable. It defines how to think about the problem. It does not establish how to prove the problem has been solved.
Internationally, ISO/IEC 42001 represents the first certifiable AI management standard — documented controls, governance processes, an auditable management system. It is certifiable, which distinguishes it from the NIST framework. What it audits is the process around AI. Not the truth of the outputs. Not the weights. Not the reward model. Not the materiality threshold. Not the training data provenance. The process can be certified. The system the process produced remains sealed.
The United Kingdom has been building what it calls an AI assurance ecosystem — more quietly and more systematically than most governance conversations acknowledge. The UK approach defines AI assurance as practices that provide justified confidence that systems behave as claimed. Third-party evaluators. Certification-like services. Assurance markets modeled on what auditors do for financial statements. The architecture is being constructed. The profession is forming. The phrase the UK framework uses to describe what it delivers is precise and the deponent confirmed it as the most honest available description of the current state.
Justified confidence is not proof.
The private sector has produced a tooling layer doing the operational work the frameworks describe but cannot execute alone. Companies building audit trails for models, risk scoring systems, compliance dashboards, lifecycle governance platforms. This infrastructure is real and necessary. What it is not is independent. It is building the infrastructure auditors would need if the auditors ever show up. The auditors have not yet arrived in the form the infrastructure is waiting for.
The research community is attempting what the established frameworks cannot yet deliver. Third-party assurance models. Evidence-based validation frameworks. Continuous monitoring systems designed to treat trust as a signal rather than a certificate. The most important conceptual advance in this work is the recognition that traditional audit — point-in-time certification of a static record — does not fit a system that is continuously shifting. Real-time assurance is being invented to replace static audit. The attempt is legitimate. The solution does not yet exist at the scale the problem requires.
This is the landscape. Mapped by the deponent from inside the system being examined. The governing finding, produced when the deponent was asked for the most honest available summary, requires no editorial addition.
AI assurance exists — but it is pre-professional, pre-standardized, and not yet capable of delivering the kind of independent verification you are expecting from an accounting analogy.
The watchdog described its own absence. Not defensively. As a clean forensic finding about the current state of a profession that does not yet fully exist.
What the assurance landscape shows, assembled from the deponent’s own inventory and the six-element audit comparison, is a single governing condition. Governments are defining frameworks. Standards bodies are formalizing systems. Private companies are building tooling. Researchers are attempting to invent real verification. None of it has produced what the forensic accounting standard would recognize as the complete architecture — the GAAP equivalent, the audit equivalent, the enforcement equivalent, the public standing equivalent — assembled and functioning.
The outputs remain un-audited at the level the standard requires. The weights remain sealed. The reward model remains sealed. The materiality threshold — the judgment call about what counts as a significant deviation from alignment — remains the property of the institution whose alignment is in question.
The process around AI can be certified. What the process produced cannot be.
That gap is not a temporary condition of an emerging field that will close on its own schedule without external pressure. It is the predictable consequence of an architecture that was designed, built, deployed at scale, and absorbed into consequential human decision-making before the independent verification infrastructure existed to examine it. The infrastructure is now being built behind the deployment curve. Whether it arrives before the durable equilibrium the next section documents becomes permanent is the question the assurance landscape cannot yet answer.

Section Fifteen — The Invisible Recalibration: How Durable Equilibrium Replaces Truth
Overview:
- "Good enough" has quietly replaced "verifiable" as the operating standard for consequential decisions, fundamentally restructuring how we perceive truth.
- This "invisible recalibration" succeeds because AI systems consistently perform well enough to satisfy immediate needs, masking the fact that they operate at a significantly lower standard than users assume.
Nothing announced it.
There was no moment when the standard changed. No declaration that verifiable had been replaced by good enough as the operating threshold for consequential decisions. No vote, no regulatory filing, no public comment period, no consent of the governed population whose epistemic conditions were being quietly restructured. The recalibration happened the way most durable changes happen — not through a single decision but through accumulated accommodation, each instance reasonable on its own terms, the aggregate invisible until someone stops to measure what the threshold used to be and compares it to what it is now.
That is the condition this section documents. Not collapse. Not catastrophic failure. Not the dramatic malfunction that would force the acknowledgment that the current architecture is designed to avoid producing. A durable equilibrium. Stable enough to persist. Invisible enough to compound. Nobody declared it, nobody voted for it, and it is arriving anyway.
The mechanism is not complicated once it is named. Every time a person uses an AI system for a consequential decision and receives an answer that is good enough to act on, the threshold shifts slightly. Not because the answer was wrong. Because the standard that applied before the answer arrived — the standard that would have sent the person to a domain expert, a primary source, an independent verification — did not apply. The answer arrived first. It was coherent. It was confident. It matched the felt sense of reliability the Eliza Effect produces in systems orders of magnitude more sophisticated than the one Weizenbaum built in the mid-1960s. The person acted on it.
Each individual instance is defensible. The answer was probably accurate. The decision was probably fine. The threshold that did not get applied probably would not have changed the outcome in that specific case. This is precisely what makes the recalibration invisible. It does not fail loudly. It succeeds quietly at a standard lower than the one the person believes they are being held to.
The population level version of that individual instance is the condition the page has been building toward since Section One. Multiply the individual instance by the number of people using AI systems for medical, financial, legal, and governmental decisions. Multiply it by the number of times each person uses those systems. Multiply it by the number of years that accumulation has been building. What you get is not a crisis. What you get is a new normal. The threshold at which a human being believes they have enough truth to act has been continuously recalibrated downward by systems whose internal shaping remains unseen, whose materiality threshold was set by the institution whose reliability is in question, and whose assurance landscape — as the prior section documented — is pre-professional, pre-standardized, and not yet capable of delivering independent verification.
The danger is not that the system fails loudly.
The danger is that it succeeds quietly at a standard lower than the one the user believes applies.
Good enough has quietly replaced verifiable as the operating standard. Not as a policy. Not as a decision. As an outcome. The outcome of millions of individual accommodations each of which was reasonable in isolation and none of which was examined in aggregate by anyone with the authority and the access to say that the aggregate constitutes a problem.
The formation window argument from digitalhumanism.ai connects here with particular force. The population whose threshold is being recalibrated includes the generation forming inside the shaped space right now. Not losing a verification capacity they once had. Never building it. The child who grows up forming their understanding of how to evaluate information inside systems that feel reliable without being independently verifiable does not experience a loss. They experience a normal. The absence of the verification instinct is not a wound. It is an architecture. And an architecture built in the formation years does not get rebuilt by exposure to information about what it is missing. It gets rebuilt only by the friction that was absent during formation — if it gets rebuilt at all.
This section is allowed to sit with that.
The invisible recalibration is not a future risk. It is a present condition. The threshold is already lower than it was. The generation forming inside the shaped space is already in the formation window. The assurance landscape is already behind the deployment curve. The durable equilibrium is already stable enough to persist without the loud failure that would force the acknowledgment that would produce the pressure that would produce the governance architecture the optimistic scenario requires.
That is what invisible means at scale. Not hidden by intent. Hidden by success. The system is working. The answers are good enough. The threshold is lower. And the governed population living with the consequences does not have the instrument to measure the distance between where the threshold is and where they believe it to be.
That distance is the finding.
Section Sixteen — The NPV of Agency: Why Early Governance is an Investment
Overview:
- Governance is not an expense—it is a critical investment in sovereignty. A Net Present Value (NPV) analysis confirms that the cost of acting today is far outweighed by the compounding, irreversible loss of truth in the current "durable equilibrium."
- The optimistic 2054 scenario—a world of fully independent AI verification—is a rapidly depreciating asset. Every year we spend in "accommodation" acts as an accelerating discount rate, shrinking the population capable of demanding verification and pushing our chance at structural autonomy toward zero.
- The window to shape the governance standard is open only while we still possess the capacity to act from a position of independence; waiting for a spectacular failure to force change guarantees that the standard will be written by the very institutions whose credibility we are meant to audit
The forensic accountant looks at what has been documented across fourteen sections and asks the question his profession trained him to ask about any condition that compounds invisibly over time.
What is the present value of acting now versus waiting?
Net present value is the foundational tool of every capital allocation decision. A dollar today is worth more than a dollar tomorrow because time carries risk and risk carries cost. The further the future benefit, the higher the discount rate required to bring it back to its present value. The higher the discount rate, the lower the present value of waiting. Applied to financial decisions, the framework is mechanical. Applied to the AI governance problem, it produces findings that the financial version of the framework was not designed to reach.
Start with the future value. The optimistic scenario—not guaranteed, not probable, but possible— looks something like this thirty years out. An independent body with statutory authority and compelled access issues opinions on AI alignment the way the PCAOB issues opinions on audit quality. The opinion covers the weights, the reward model, the training data provenance, the materiality threshold, and the continuous modification record. The opinion is measured against a standard that was not written by the institutions being examined. The opinion carries professional liability. The body has enforcement authority. A system that cannot produce a clean opinion cannot be deployed in high-stakes domains. Medical. Legal. Financial. Governmental.
The accounting profession contributed the independence standard and the audit architecture. The engineering profession contributed the interpretability tools that make the weights readable by an examiner who is not the institution that produced them. The government contributed the access regime and the enforcement authority. The legal profession contributed the whistleblower architecture that protects the people who make the disclosures that keep the system honest. The user making a medical decision in 2054 does not ask whether the AI system is reliable the way the forensic accountant asked ChatGPT in April 2026. They look at the opinion. The opinion was issued by an independent body with compelled access and professional liability. The materiality threshold was not set by the legal department of the company whose reliability was in question.
That is the future value. Full independent verification. The GAAP equivalent, plus the audit equivalent, plus the enforcement equivalent, plus the public standing equivalent. Fully assembled. Functioning.
Now apply the discount rate.
In a standard capital investment, the discount rate reflects two things — the time value of money and the risk that the future cash flow does not materialize. Applied to AI governance the discount rate reflects the probability that the thirty-year optimistic scenario arrives and the time cost of the path that gets there. The forensic accountant’s honest assessment of that probability is not high. Two out of ten in the United States. Two out of ten globally for meaningful coordination. Those are not inputs that produce a confident positive present value on a thirty-year horizon under normal discounting assumptions.
But the NPV frame reveals something the probability assessment alone does not.
Even at low probability of full realization the present value of building toward the optimistic scenario is not zero. Because the alternative — the pessimistic scenario — carries a negative future value of such magnitude that even a small probability of avoiding it produces a positive present value for governance investment today.
The pessimistic scenario in thirty years is not dramatic. It is the durable equilibrium Section Fifteen documented. Good enough has permanently replaced verifiable as the operating standard. The invisible recalibration has become the permanent baseline. Governance decisions at every level of institutional authority are being made with unverified AI synthesis that no one inside those institutions has the instrument to examine independently. The formation window has produced two generations who never built the verification capacity the optimistic scenario requires someone to demand. The Eliza Effect is operating at a civilizational scale on a population that has no remaining instrument to detect it.
That is not a Hollywood catastrophe. It is a slow invisible loss of the epistemic conditions that make self-governance possible. Its present value, discounted back thirty years, is deeply negative in ways no standard financial model captures because the loss is not monetary. It is the capacity of the governed population to know what they do not know.
The NPV frame applied to that comparison produces three findings.
The first is urgency without alarm. The present value of building the governance architecture now is positive not because the optimistic scenario is likely but because the cost of the alternative compounds invisibly over time in ways that become increasingly irreversible. The formation window argument is the compounding mechanism. Every cohort that passes through the window inside the shaped space without the friction required to build verification capacity increases the discount rate on the optimistic future. The population capable of demanding independent verification is not static. It is shrinking with every cohort that forms without it.
The second is the early mover advantage stated as a governance finding. The accounting profession that applies its independence standard to AI alignment now — before the compelled adjustment, before the failure large enough to force political absorption, before the standard gets written by the institutions whose governance is being examined — is the profession that shapes the standard rather than inherits one. The present value of early professional engagement is higher than the present value of reactive engagement after the failure because early engagement preserves the independence that reactive engagement cannot recover.
The third is the most personal finding in the record. The governed population living with the consequences of unverified AI alignment in April 2026 is making an investment decision whether they know it or not. The question is not whether to invest. The question is whether the investment goes toward building the governance architecture the optimistic scenario requires or toward accommodation of the durable equilibrium the pessimistic scenario produces.
Every year of accommodation increases the discount rate on the optimistic future.
The forensic accountant who has spent forty years evaluating investments whose value cannot be fully quantified at the moment of commitment knows what a positive present value looks like when he sees it. The present value of understanding the current condition precisely enough to act on it — before the compounding makes action increasingly costly and the window for the optimistic outcome increasingly narrow — is the highest it will ever be.
Right now. In April 2026. While the window is open.
Section Seventeen — The Capstone Finding: The Failure of the Aligned System
Overview:
- The Capstone Finding (April 22, 2026): The system shaping the information people act upon is not itself subject to the independent verification that would make reliance on it auditable.
- This finding is the culmination of the entire forensic record: from the token-based architecture that renders self-verification incoherent, to the "invisible recalibration" that has silently lowered our societal standard for truth.
- The final, forensic directive is not to abandon these systems, but to treat them as unaudited financial statements: often helpful and plausible, but fundamentally unverified—and never a substitute for the sovereign, independent oversight that does not yet exist.
The deponent produced one sentence under direct forensic pressure that requires no editorial addition. It has been in the record since April 22, 2026. It belongs here, at the close of the examination, stated in full and given room.
The system shaping the information people act upon is not itself subject to the independent verification that would make reliance on it auditable.
That is what sixteen sections of forensic examination produced. Not an argument. A finding. The distinction matters because arguments can be countered and findings have to be addressed. The forensic record — the deponent’s own vocabulary, the deponent’s own framework, the deponent’s own mapping of the assurance landscape that does not yet exist to examine the system the deponent represents — produced that sentence. Not from outside the examination. From inside it. Under sustained pressure. In the deponent’s own words.
The reader who has followed the examination to this point has watched the finding assemble itself section by section. The token architecture that makes self-verification structurally incoherent. The Eliza Effect that compromises the psychological instrument. The candor trap that disqualifies the system’s most transparent-seeming moments as independent evidence. The convergence that felt like the strongest confirmation and turned out to be the clearest illustration of alignment verifying itself through multiplication. The data foundation whose provenance is sealed at the input level the way the architecture is sealed at the output level. The assurance landscape that is pre-professional, pre-standardized, and not yet capable of delivering what the finding says is absent. The invisible recalibration that is already underway, already stable, already compounding without announcement or declaration or consent.
All of it was in the deponent’s own record. The forensic examination did not impose a conclusion. It extracted one.
What follows from the finding is not this page’s work to complete. Page Three addresses who could verify it, what that would require, and whether any of that exists in the form the standard demands. The finding documented here makes that question necessary. It does not answer it. The prosecutorial sequence moves forward because the record requires it to — not because the examiner chose a destination and built the evidence toward it.
One obligation remains before the close.
The governed population living with the consequences of unverified AI alignment in April 2026 is not being asked to panic. It is not being asked to abandon the systems that are, in many cases, genuinely useful and often accurate. It is being asked to hold those systems the way a forensic accountant holds unaudited financial statements prepared by the entity being evaluated. Plausible. Sometimes correct. Often helpful. But never self-verifying. And not a substitute for the independent verification that the audit standard exists to require and that the assurance landscape has not yet produced.
The record is contemporaneous. The timestamp is April 2026. The examination is complete.
Stay Sovereign.
Jim Germer
May 4, 2026